Want to watch English videos in Telugu? IIIT-Hyderabad researchers have the answer
By Newsmeter Network
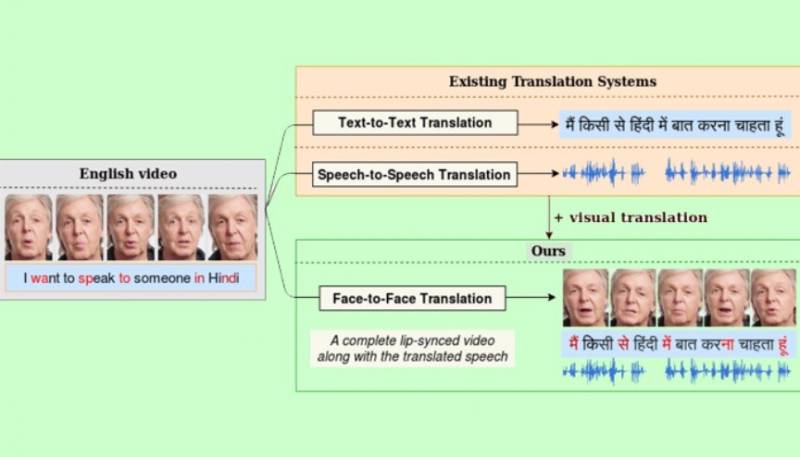
Hyderabad: A team of researchers from the International Institute of Information Technology (IIIT), Hyderabad, has come up with an exciting innovation, automatic face-to-face translation, which enables video content generation on a large-scale. It will automatically translate English videos into regional languages on-the-go using automatic speech recognition as well as neural machine translation models.
Prof. Jawahar and his students Prajwal K. R, Rudrabha Mukhopadhyay, Jerrin Phillip, and Abhishek Jha, in collaboration with Prof. Vinay Namboodiri from IIT Kanpur, worked on translation research culminating in a research paper titled ‘Towards Automatic Face-to-Face Translation’ which was presented at the ACM International Conference on Multimedia at Nice, France, in October 2019.
What makes this innovation unique is how the researchers have incorporated visual recognition tools in the field of translation. While Google mostly uses aural tools for speech recognition and translation, the ‘automatic face-to-face translation tool’ plans on using a combination of both visual and aural speech recognition methods.
Prof. Jawahar says, “Manually creating vernacular content from scratch, or even manually translating and dubbing existing videos will not match the rate at which digital content is being created. That’s why we want it to be completely automatic. We want the right educational content to reach the rural masses. It could be ‘How To’ videos in sectors such as agriculture, ‘How To Repair or Fix’ things and so on. But this may take time, so we thought why not start with entertainment, like movies and TV shows? Once we have the right framework in place, it’s easy to create other content.”
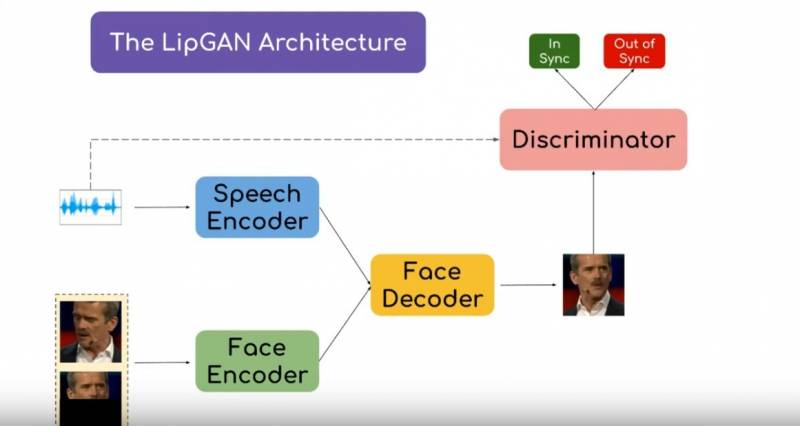
The researchers have also come up with a solution to fix out-of-sync lip movements in a translated video. Working on the speech-to-speech translation systems, a video in a source language will be delivered into a video in the target language so that the voice style and lip movements match the target language speech. To obtain a fully translated video with accurate lip synchronization, the researchers introduced a novel visual module called LipGAN. However, challenges in proper translation arise when the faces in the video are moving, the researchers said. Nevertheless, they believe that this innovation can be used in multiple fields such as cross-lingual video calls, and assisting hearing-impaired individuals with lip-reading, word-spotting, and so on.